文章编号:1006—9860(2020)01—0085—08 中图分类号:G434 文献标识码:A 近年来,大数据(Big Data)为社会科学的发展带来了极大的机遇,计算社会科学是大数据时代社会科学发展的必然结果。所谓大数据时代,就是“以系统数据为基础充分而深入挖掘数据内在关系”[1]。过去人类获取的社会数据是有限的、间段的、片面的,但随着收集和处理海量的社会数据能力的空前提升,旧的范式无法解决太多的问题而出现了“科学危机”,新的社会科学研究范式呼之欲出。教育学作为社会科学的一个种类,必然无法回避范式转型的浪潮,如今,计算教育学仍是一个处在萌芽期的新生事物,要正确、全面地认识教育学的这一分支,就要把握住计算社会科学总的发展脉络,明确大数据的范式特征。 一、大数据与计算社会科学 大数据催生了计算社会科学这门新兴的学科,通过学科交叉帮助人们更好地认识复杂社会现象背后的规律和作用机理,计算社会科学打破了自然科学与社会科学的长期隔离,是一种数据驱动的研究范式,背后是自下而上的思维方法,是对传统研究范式的超越。 (一)核心概念辨析 大数据时代的到来带来了很多新生的概念,“大数据”本身就是一个内涵丰富且值得推敲的核心概念,除此之外还有“数据密集型计算(Data Intensive Computing)”“社会计算(Social Computing)”“计算社会科学(Computational Social Science)”等等,这些概念在实际研究中存在着不同程度的模糊和混用的情况,因此,急于将新范式投入具体学科是不明智的,正确定位核心概念、厘清概念间的关系是深入到社会学、教育学、经济学、政治学等具体学科的前提。 首先,关于“大数据”与“数据密集型计算”是一组容易在研究中混用的概念,将二者等价抑或是都视为研究范式的观点是不合理的。有研究者曾对此做过专门的辨析,并对“数据密集型计算”做了严格的界定,数据是其核心,系统负责获取用以维护持续改变的数据集,实现大数量并行计算和处理[2]。从定义中我们不难发现,数据密集型计算是数据获取到管理再到分析、理解的过程[3],其本质是一种方法。相比之下,大数据并无明确的定义,因为“大”本身就是一个相对的概念,研究者多是从大数据特征出发进行描述。董春雨教授在综述国外研究的基础上提出“大数据是一种思维方式、一种世界观理解世界的方式”[4]。严谨地看,这种定义是准确的。库恩认为,“范式”内在地包含了信仰、价值、技术等方面,是某一共同体中的个体共同遵从的世界观和行为方式,也是常规科学要紧密依赖的理论基础和实践规范[5]。依从库恩的界定,技术是范式的重要组成部分,而方法是技术层面的核心,可以说,研究方法是范式的重要表现形式,方法的选择与转变的背后是价值观念、思维模式的转型,不同方法在研究中的“此消彼长”正是哲学思想的涌动。而哲学界产生的“计算主义思潮”成了大数据范式的思想基础,这一思潮包含着“宇宙是一部巨型计算装置”“整个世界是由算法控制”的隐喻,自然规律作用于计算过程,进而支配着一切自然事件,事物之所以呈现出多样性均是源于算法复杂程度的不同[6]。美国计算机图灵奖得主吉姆·格雷(Jim Gray)把科学研究走过的阶段分为经验科学、理论科学、计算科学和数据密集型科学[7],相对应的,18世纪以前为经验范式,18-19世纪为理论范式,20世纪中期到21世纪初为模拟范式,本世纪初至今为第四范式。尽管各国由于技术水平、理论水平、研究传统等多方面的差异,时间段的划分不一而同,但是可以确定的是,如今我们正在经历着由计算科学向大数据科学的过渡,这一变化的发生冲击着科学研究的各个领域。而从定义入手,数据密集型计算显然是一种数据处理方法,它与大数据的关联就在于,这是大数据处理的核心方式非唯一方法,绝不是包含了世界观的时代转型,更不是科学革命意义上的“范式”。 “社会计算”与“计算社会科学”是两个重要的概念,其中社会计算进入人类社会总体上有两方面的动因,一方面是社会系统中的复杂社会现象需要复杂性科学理论来描述,另一方面是计算机作为基本研究工具,用以解决复杂性问题成为可能。自1994年社会计算第一次被提出起,不断有学者对其内涵做出阐述,总体上围绕两个方面:计算设备发挥着交流媒介的作用,目的是理解社会过程。总体上讲,社会计算有两种发展趋势,一是面向社会科学,二是面向技术应用[8]。计算社会科学属于前者,是面向社会科学的社会计算的一个具体研究领域,与之相并列的还有社会网络分析等等。从本质上讲,社会计算既不属于自然科学,也不属于社会科学,曾有研究者将三者关系绘制如图1所示,社会科学与自然科学的长期分离被形象喻为相对的两岸,自然科学居于河的左岸,是以科学计算为核心研究范式;社会科学居于右岸,包括心理学、经济学、传播学、社会学、政治学等[9]。社会计算正是自然科学与社会科学的沟通与联手,以互联网兴起、在线实时数据的公开为前提,以数据挖掘为核心技术,计算社会科学作为其中的研究领域之一,近年在Science和Nature等顶级期刊上亦有成果不断涌现。大卫·拉泽(David Lazer)等15位美国学者在Science联合发表了《计算社会科学》(Computational Social Science)[10],吉姆·贾尔斯(Jim Giles)在Nature发表最新进展的研究综述《计算社会科学:建立联系》(Computational Social Science:Making the Links)[11],这些具有里程碑意义的研究标志着计算社会科学时代的兴起。
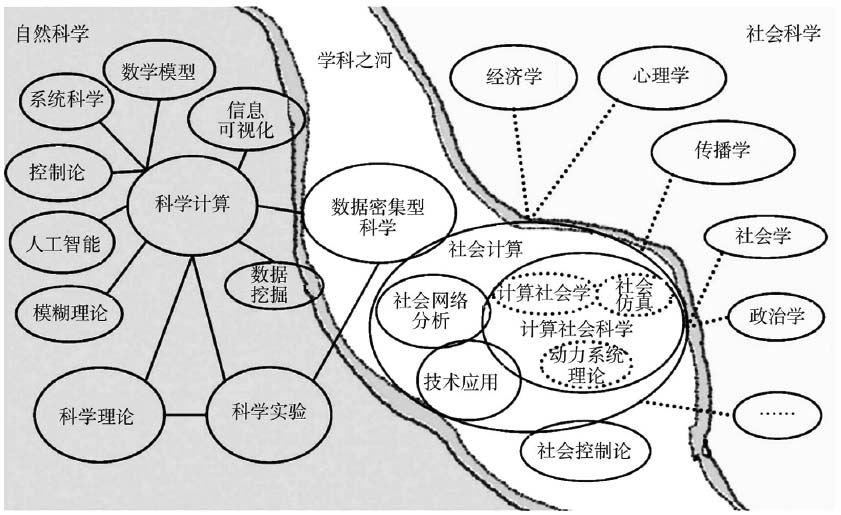
图1 学科分类的河流比喻[12] (二)计算社会科学对传统研究的超越 从宏观上的学科分野上看,计算社会科学对传统研究的超越表现在它打破了自然科学与社会科学的长期隔离。由于思维方式的差异,图1中“两岸”长期处于对垒状态,社会科学是“总体逻辑思维”,关注独立个案的整体分布,将变异视为社会现实的本质。不同的是,自然科学是“类型逻辑思维”,关注典型现象,并将其呈现出的规律加以概括,进而推广到个体和具体问题[13]。直到20世纪50年代之前,两者仍是相对独立的,直到信息革命开始,人类面临的问题愈发复杂,社会科学与自然科学研究者开始意识到,仅仅立于岸的一边是无法揭示问题的实质的。以社会科学研究为例,复杂的社会问题需要结束严谨的数学方法进行求解,特别是随着互联网的发展和计算机性能的提升,大数据的获取与处理成为可能,过去无法处理的问题在新范式下找到了解决的突破口,而这种全新的范式正是“大数据”,自然科学和社会科学开始走到一起联手面对社会问题。具体到研究范式,大数据范式在我国仍是一个新生事物,但它对社会科学领域产生的影响已是不争的事实。为进一步提炼其特征,将传统研究范式与计算社会科学的新范式进行对照,如表1所示。