武汉大学机构用户,欢迎您!
偶发学习是一种重要的非正式学习方式。随着信息偶遇研究的兴起,基于信息偶遇的在线偶发学习正在逐步引起研究者的关注。以信息偶遇及其相关模型为切入点,对基于信息偶遇的在线偶发学习进行了概念解析,以意义建构理论和心流理论为基础,分学习前、学习中和学习后三个阶段对基于信息偶遇的在线偶发学习的内在机理进行了系统探索,从学习者、偶遇信息、学习环境、信息技术四个维度剖析了基于信息偶遇的在线偶发学习的影响因素。研究结果对进一步探明在线偶发学习的发生机制和行为模式具有一定参考价值。
 图1 信息偶遇过程模型 (二)信息偶遇与信息行为嵌套模型 Wilson于1999年提出了信息行为嵌套模型来描述信息行为、信息寻求与信息搜索之间的关系。在该模型中,Wilson将信息行为定义为“与信息操作有关的所有行为,同时包括主动和被动的信息寻求和利用”[6],相比之前的其他定义,该定义强调了被动信息获取是信息行为的重要组成部分。信息寻求作为信息行为的子集,则是指人们致力于发现、获取信息资源的各种行为方式的总和。虽然Wilson强调了被动信息获取的重要性,但并未将信息偶遇行为包含在模型中。直到2015年,Agarwal首次将信息偶遇引入到信息行为模型中,提出了一个扩展的信息行为嵌套模型[7],如图2所示。在扩展后的模型中,信息偶遇与其他各类信息行为一起构成了信息行为的整体组成框架。同时我们可以注意到,信息偶遇与信息寻求及信息搜索之间存在交集,这表明信息偶遇发生的情境并非单一。信息偶遇行为对情境具有一定适应性,就其属性而言主要以被动信息获取情境为主,但也可以少量存在于主动信息获取情境中。
图1 信息偶遇过程模型 (二)信息偶遇与信息行为嵌套模型 Wilson于1999年提出了信息行为嵌套模型来描述信息行为、信息寻求与信息搜索之间的关系。在该模型中,Wilson将信息行为定义为“与信息操作有关的所有行为,同时包括主动和被动的信息寻求和利用”[6],相比之前的其他定义,该定义强调了被动信息获取是信息行为的重要组成部分。信息寻求作为信息行为的子集,则是指人们致力于发现、获取信息资源的各种行为方式的总和。虽然Wilson强调了被动信息获取的重要性,但并未将信息偶遇行为包含在模型中。直到2015年,Agarwal首次将信息偶遇引入到信息行为模型中,提出了一个扩展的信息行为嵌套模型[7],如图2所示。在扩展后的模型中,信息偶遇与其他各类信息行为一起构成了信息行为的整体组成框架。同时我们可以注意到,信息偶遇与信息寻求及信息搜索之间存在交集,这表明信息偶遇发生的情境并非单一。信息偶遇行为对情境具有一定适应性,就其属性而言主要以被动信息获取情境为主,但也可以少量存在于主动信息获取情境中。 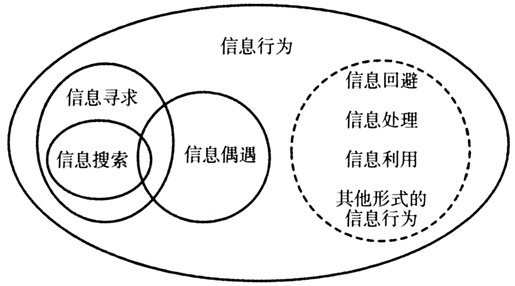 图2 扩展的信息行为嵌套模型 (三)信息偶遇感知模型 在信息偶遇感知模型的研究中,较有代表性的是Lawley和Tompkin从感知角度提出的信息偶遇感知模型,如图3所示。该模型将信息偶遇的感知过程分为6个关键事件(Key Event)。图中E表示信息偶遇事件,如果E后面带“-”号,表示该事件处于信息偶遇事件发生前的时间;E后面带“+”号,表示处于信息偶遇事件发生后的时间。具体来说,“E-1”是信息偶遇准备阶段,表示用户做好了信息偶遇的心理和情绪准备;“E+1”表示对偶遇信息的潜力、价值和有用性进行识别;“E+2”表示把握信息获取的机会,再次确认偶遇信息的潜在价值;“E+3”表示明晰偶遇价值并采取后续行为,进一步放大偶遇信息的潜在效果,力图实现效果最大化;“E+4”表示对信息偶遇后的效果和影响进行评估,并根据评估效果对偶遇信息的潜力和价值进行反思[8][9]。其中,“E+1”“E+2”以及“E+3”“E+4”这四个阶段是循环迭代的,形成了信息偶遇感知的闭环结构。
图2 扩展的信息行为嵌套模型 (三)信息偶遇感知模型 在信息偶遇感知模型的研究中,较有代表性的是Lawley和Tompkin从感知角度提出的信息偶遇感知模型,如图3所示。该模型将信息偶遇的感知过程分为6个关键事件(Key Event)。图中E表示信息偶遇事件,如果E后面带“-”号,表示该事件处于信息偶遇事件发生前的时间;E后面带“+”号,表示处于信息偶遇事件发生后的时间。具体来说,“E-1”是信息偶遇准备阶段,表示用户做好了信息偶遇的心理和情绪准备;“E+1”表示对偶遇信息的潜力、价值和有用性进行识别;“E+2”表示把握信息获取的机会,再次确认偶遇信息的潜在价值;“E+3”表示明晰偶遇价值并采取后续行为,进一步放大偶遇信息的潜在效果,力图实现效果最大化;“E+4”表示对信息偶遇后的效果和影响进行评估,并根据评估效果对偶遇信息的潜力和价值进行反思[8][9]。其中,“E+1”“E+2”以及“E+3”“E+4”这四个阶段是循环迭代的,形成了信息偶遇感知的闭环结构。