武汉大学机构用户,欢迎您!
大数据时代的来临,引领学习者学习方式发生变革,基于大数据学习分析技术的个性化学习成为教育学和认知科学的研究趋势。提供给学生有针对性的个性化学习是教育发展方向,是技术回归教育本质的实践。大数据应用需要经历数据收集、数据分析和数据可视化等三个必要阶段;大数据学习分析对个性化学习中的教师、学生和教育管理者等利益相关者均产生积极的影响;大数据对实现个性化学习的价值体现在五个方面:完善个性化的学习者档案、分析预测个性化的学习行为、优化个性化的教育决策、改善个性化的学习评估、提供个性化的学习反馈及建议。最后采用德尔菲法、头脑风暴法构建了基于大数据的个性化学习体系框架。利用大数据学习分析反思教育现状,对推动个性化学习的研究具有重要意义,同时将大数据视为一种新的思维方式和学习路径,需要辩证地看待其优势和劣势。
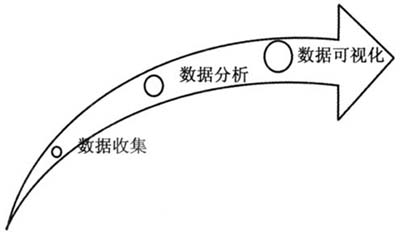 图1 挖掘大数据价值三个阶段 (一)数据收集 数据收集是挖掘大数据巨大价值的第一步。个性化学习往往因为片段化不全面的数据信息而不能为学生提供一个良好的发展机会,并且因为缺乏可靠依据而过于依赖经验判断。大数据意味着对海量的复杂数据进行全面的收集,包括结构化与非结构化数据的收集。数据收集可以采用不同的方法。例如Hadoop的Chukwa、Cloudera的Flume以及Facebook的Scribe等系统日志收集方法采用分布式框架,实现每秒数百MB日志数据的收集与传输。网络数据收集方法通过网络爬虫或网站公开API等方式从网站上获取数据信息,实现将非结构化数据从网页中抽取出来,以结构化的方式存储为统一的本地数据文件,支持图片、音频、视频等文件或附件的收集,附件与正文可以自动关联。随着日益增长的海量数据被收集并存储在各种数据库中,我们需要对数据进行数据识别,发现有价值的信息。 (二)数据分析 数据分析包括整合、分类、关联分析等操作,形成分析结果,用于预测学习行为、优化教育决策、改善学习评估、提供学习反馈及建议等。当数据被转换成一个可用的形式之后,将分析数据生成可利用信息。数据分析需要实时的数据处理,主要有流处理、批量处理以及两种模式融合等三种思路。例如,MapReduce是Google公司最早提出的典型批处理模式,首先将用户原始数据分块处理,再交由不同的Map任务区处理。此外,Power Drill与Dremel均为Google公司的大数据处理工具。未来的大数据分析方面,将更多地采用流处理与批处理融合的方式,已有研究利用MapReduce模型实现了快速流处理的同时也能够支持大规模静态数据的处理,兼具了流处理与批处理两种模式的特征[5]。数据分析依据海量与学生相关的可利用信息,分析其隐含的关联并准确地预测学生发展趋势,促进学生个性化发展。随着数据的内容日趋多样化,管理和分析多样的数据集成为一个非常复杂的过程,这种情况称为大数据的“复杂性”。
图1 挖掘大数据价值三个阶段 (一)数据收集 数据收集是挖掘大数据巨大价值的第一步。个性化学习往往因为片段化不全面的数据信息而不能为学生提供一个良好的发展机会,并且因为缺乏可靠依据而过于依赖经验判断。大数据意味着对海量的复杂数据进行全面的收集,包括结构化与非结构化数据的收集。数据收集可以采用不同的方法。例如Hadoop的Chukwa、Cloudera的Flume以及Facebook的Scribe等系统日志收集方法采用分布式框架,实现每秒数百MB日志数据的收集与传输。网络数据收集方法通过网络爬虫或网站公开API等方式从网站上获取数据信息,实现将非结构化数据从网页中抽取出来,以结构化的方式存储为统一的本地数据文件,支持图片、音频、视频等文件或附件的收集,附件与正文可以自动关联。随着日益增长的海量数据被收集并存储在各种数据库中,我们需要对数据进行数据识别,发现有价值的信息。 (二)数据分析 数据分析包括整合、分类、关联分析等操作,形成分析结果,用于预测学习行为、优化教育决策、改善学习评估、提供学习反馈及建议等。当数据被转换成一个可用的形式之后,将分析数据生成可利用信息。数据分析需要实时的数据处理,主要有流处理、批量处理以及两种模式融合等三种思路。例如,MapReduce是Google公司最早提出的典型批处理模式,首先将用户原始数据分块处理,再交由不同的Map任务区处理。此外,Power Drill与Dremel均为Google公司的大数据处理工具。未来的大数据分析方面,将更多地采用流处理与批处理融合的方式,已有研究利用MapReduce模型实现了快速流处理的同时也能够支持大规模静态数据的处理,兼具了流处理与批处理两种模式的特征[5]。数据分析依据海量与学生相关的可利用信息,分析其隐含的关联并准确地预测学生发展趋势,促进学生个性化发展。随着数据的内容日趋多样化,管理和分析多样的数据集成为一个非常复杂的过程,这种情况称为大数据的“复杂性”。